You may have seen Microsoft backed OpenAI Dalle’s ability to generate images from prompts, such as this prompt: “a cat working on a robot in cartoon style”:

But how is this possible for ai to understand what we want it to draw, and draw a realistic and convincing image? The answer is a breakthrough technique known as stable diffusion. In this post, we’ll explain the answer to how does an ai draw and how does ai create images using stable diffusion.
Explain Stable Diffusion Like I’m Five
Imagine you have a magic drawing machine that can create pictures. But instead of drawing the whole picture at once, it starts with a blank canvas and adds tiny details bit by bit. It’s like building a picture piece by piece.
Stable diffusion is like a rule for the magic drawing machine. It tells the machine how to add each tiny detail to the picture in a smooth and balanced way. It helps the machine make sure that every part of the picture gets attention and that nothing gets too messy or blurry.
You know how when you color a picture, you start with light colors and then add darker colors to make it look better? Stable diffusion is a bit like that too. It helps the machine start with simple and basic shapes and colors and then gradually adds more complexity and details.
By following this recipe of stable diffusion, the machine can create images that look very realistic and beautiful, just like the pictures you see in books or on your tablet. It’s a clever way for computers to make amazing pictures step by step, making sure everything looks great along the way.
Stable Diffusion Explained
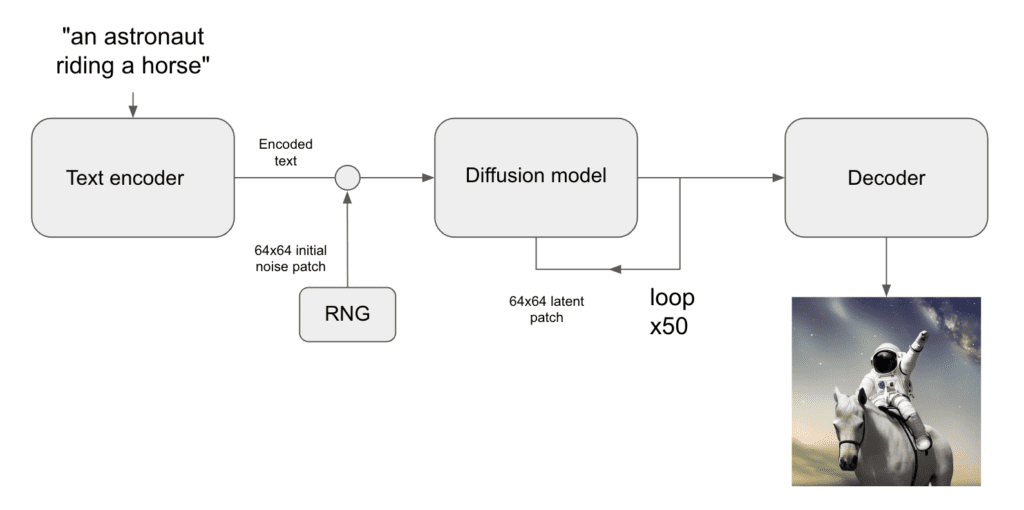
Stable diffusion that allows text to be converted to an image and answers “how does AI draw?” works through 2 main steps:
- The text request is converted into a format that can be used as input to a pre-trained diffusion model
- The diffusion model is run on the input, and the output is then fed back into the diffusion model a select number of times until the output image is fully created, in what is known as the diffusion process
1. The Stable Diffusion Model is Trained
A stable diffusion model, specifically for image generation, refers to a type of generative model that produces high-quality, coherent images by iteratively refining them through a diffusion process. The training process for such models typically involves two main steps: pre-training and fine-tuning. This model the backbone that allows an ai to draw. I’ll provide a high-level overview of these steps below:
- Pre-training:
- The pre-training phase involves training a model to predict the next step of a randomly corrupted image, given the current step. This process is often performed using a variant of the autoregressive model called a “denoising score matching” model or “contrastive predictive coding” model.
- The pre-training step helps the model learn the statistics and underlying structure of the image dataset, enabling it to capture the high-level features and textures present in the images.
- Fine-tuning:
- Once the pre-training is complete, the model is fine-tuned using a technique called “diffusion.” Diffusion is an iterative process that refines an image by gradually adding Gaussian noise to it and allowing the model to remove the noise and restore the original image.
- During the diffusion process, the model learns to handle noise and capture the fine details in the images.
- The fine-tuning step aims to optimize the model’s parameters by minimizing the difference between the generated images and the ground truth images in the training dataset.
- This optimization is typically performed using maximum likelihood estimation or variational inference techniques.
The training of a stable diffusion model for image generation involves iterating through multiple diffusion steps, where the noise level gradually increases. Noise can be applied to an original image, and then the understanding of what that same image with noise can be created, allowing the model to then take a noisy image and restore the original. This training process can be visualized with noise applied to an image of a dog, with the model learning the image with slightly more noise every iteration:

Each diffusion step involves passing the image through the model, which applies a sequence of transformations to reduce the noise and generate a refined image. Because the model understands how an image looks with noise, it symmetrically understands how an image looks without noise.
The stability of the diffusion model is crucial to ensure that the generated images remain coherent and visually pleasing throughout the diffusion process. Techniques such as careful architectural design, regularization methods, and loss function design are employed to maintain stability and prevent image degradation as the diffusion progresses.
Overall, the training of a stable diffusion model for image generation combines pre-training to capture high-level features and fine-tuning through a diffusion process to refine the images while maintaining stability. This iterative approach helps generate realistic and coherent images with intricate details.
2. The diffusion process runs, converting noise into the goal image text
Once the stable diffusion model is fully trained, It is capable of taking a “noisy” image and slightly removing the noise from the image. As a result, any image starts with noise, and the model slowly removes the noise by passing the less noisy image back into the model that removes noise until the goal image is reached, such as a sunflower:
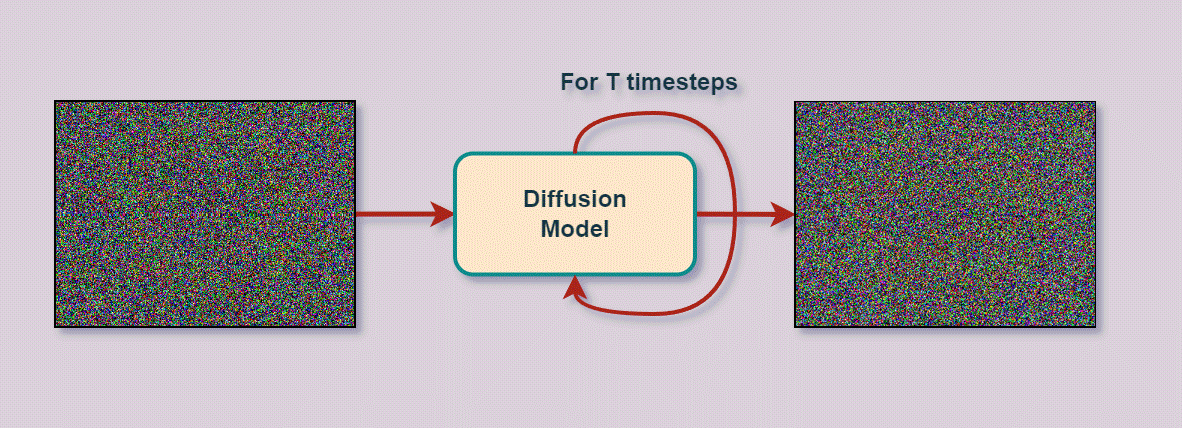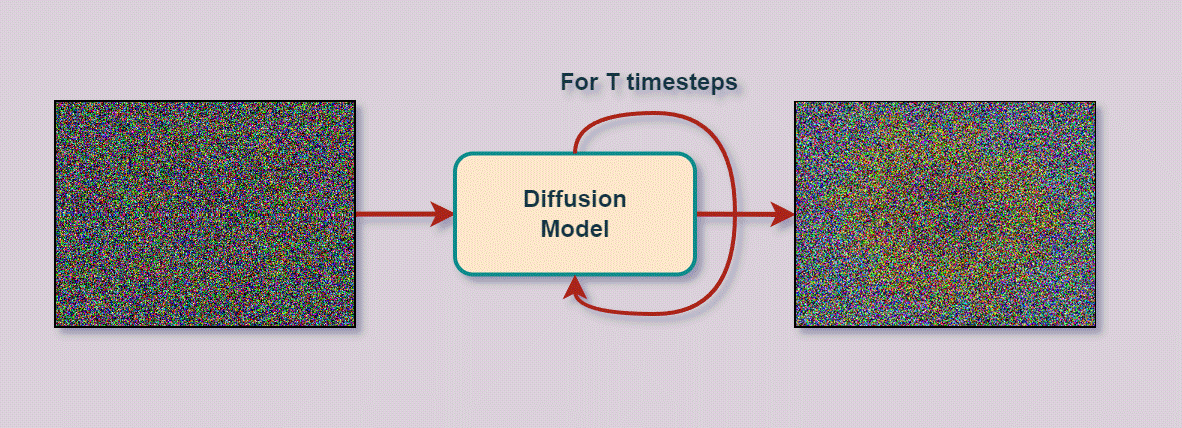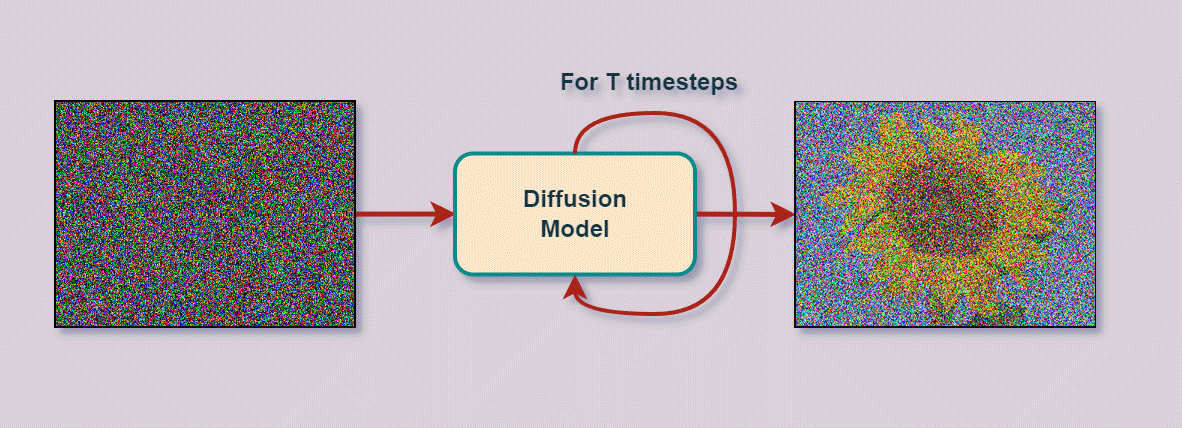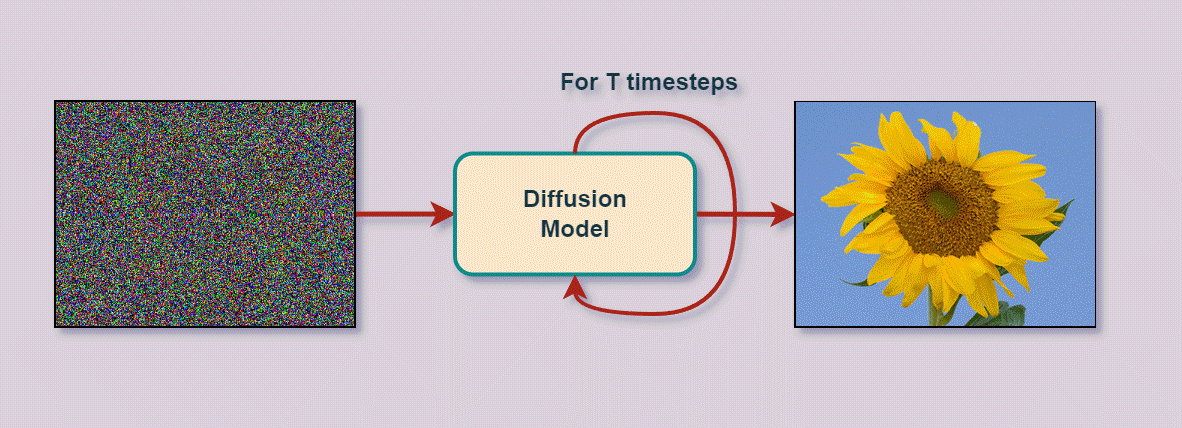
At every iteration, the model removes slightly more noise, and this image with slightly less noise is fed back into the model, iteratively removing more noise and restoring properties of the original image matching the input goal text description. We can see this process visualized with an example of a dog:

Optionally, after generating an image using a stable diffusion model, the autoencoder decoder can be used to refine or improve the quality of the generated image. The decoder takes the generated image as input and attempts to reconstruct the original image. This post-processing step can help remove artifacts, enhance details, or improve overall image quality.
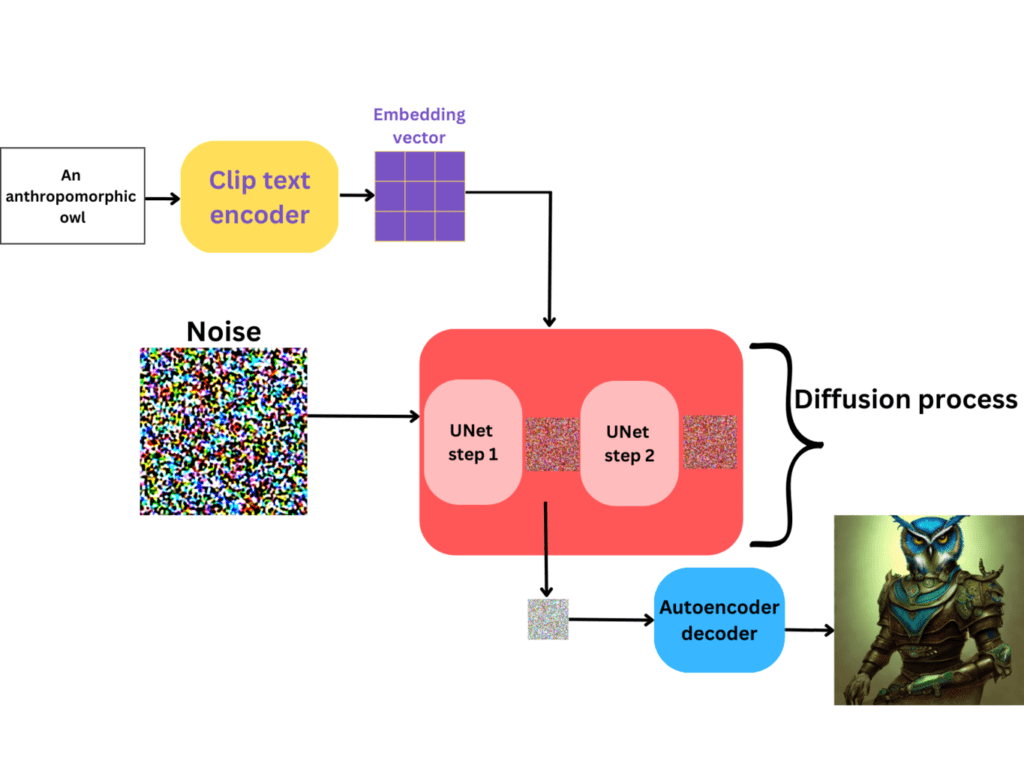
We hope with this post you’ve learned how ai is able to draw and how ai can create images using the process known as stable diffusion!





